R&D PiirZ — 2026
PAIR
Advanced Information
Retrieval
Tre layer sinergici che sostituiscono il RAG tradizionale con conoscenza compilata, relazioni esplicite e memoria persistente.

Tre layer sinergici che sostituiscono il RAG tradizionale con conoscenza compilata, relazioni esplicite e memoria persistente.
Embedding vettoriali, chunking e vector database sono diventati lo standard. Ma sotto la superficie nascondono limiti strutturali.
Il retrieval basato su similarità vettoriale è opaco. Non puoi ispezionare perché un chunk è stato selezionato.
I documenti vengono spezzati in modo arbitrario, perdendo contesto e relazioni tra concetti.
Ogni query invia grandi blocchi di testo non strutturato nel context window dell'LLM.
Gli agenti non ricordano nulla tra sessioni. Ogni conversazione riparte da zero.
I documenti sono trattati come testo piatto. Nessuna mappa delle relazioni tra entità e concetti.
PAIR non migliora il RAG. Lo sostituisce con un approccio strutturato, ispezionabile e cumulativo.
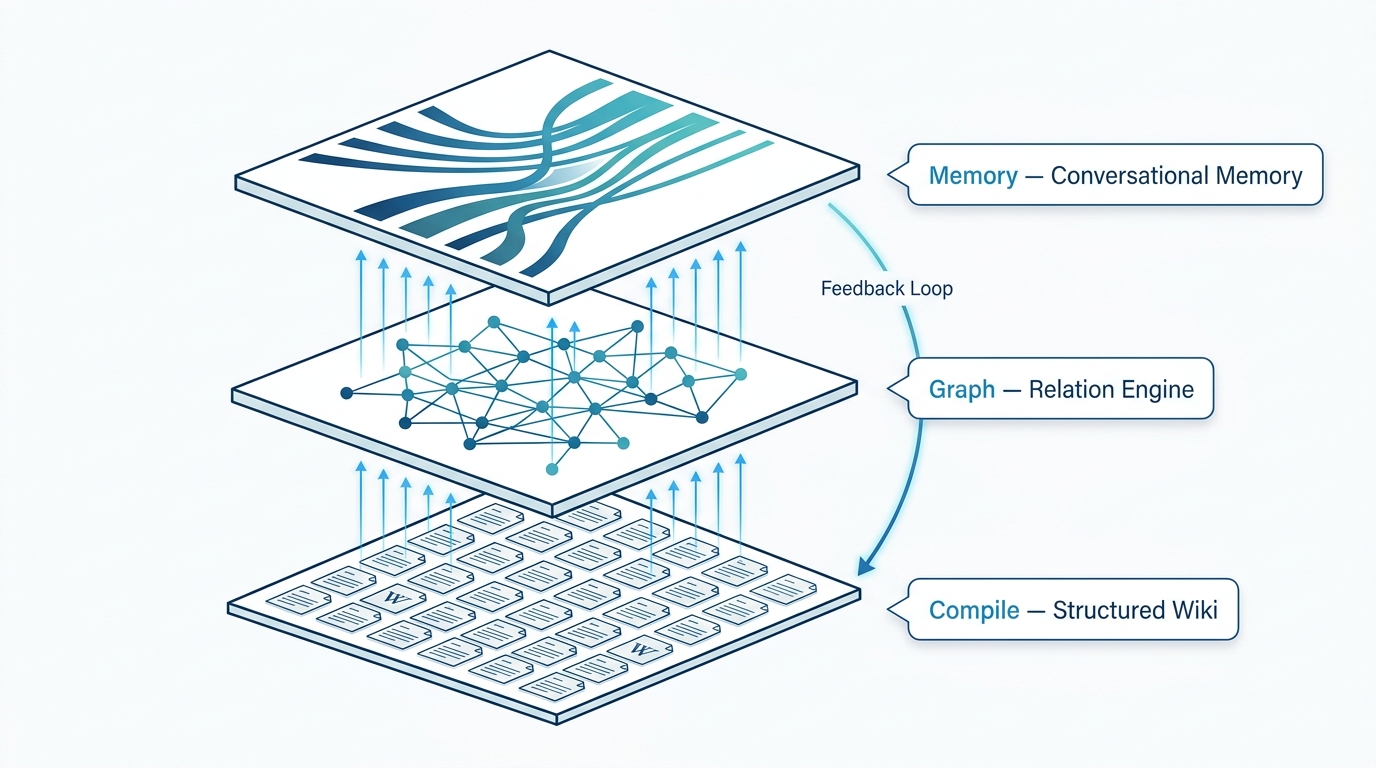
Documenti raw → wiki strutturata con indici, backlink e cross-reference. Mantenuta incrementalmente.
Knowledge graph relazionale con community detection, confidence tagging e query MCP.
Memoria conversazionale persistente con retrieval a 4 livelli e tunnel cross-dominio.

I documenti raw — PDF, pagine web, paper, codice — vengono analizzati e compilati in una wiki markdown strutturata. File indice, articoli concettuali, backlink e cross-reference. Ogni nuovo documento aggiorna solo quello che serve, senza riprocessare l'intero corpus. Un lint automatico verifica inconsistenze e suggerisce nuovi articoli.
Il codice viene analizzato con parsing AST deterministico su 14 linguaggi. Documenti e immagini vengono processati da subagent AI in parallelo. Il risultato è un knowledge graph con community detection (Leiden), confidence tagging su ogni relazione — EXTRACTED, INFERRED, AMBIGUOUS — e god node detection.

Le conversazioni vengono salvate in una struttura navigabile per dominio, progetto e topic. Al risveglio l'agente riceve un briefing a 600 token. Il retrieval opera su 4 livelli: Identity, Essential, On-demand, Deep search. I tunnel cross-dominio trasferiscono conoscenza tra progetti.
Ogni interazione arricchisce lo stack. PAIR non è statico: è un sistema a conoscenza cumulativa.
Il cliente carica documenti, codice, paper, note
L'LLM compila wiki strutturata con indici e backlink
Il motore relazionale estrae grafo con community e confidence
L'agente interagisce, accumula sessioni e recupera contesto
Query → wiki. Relazioni → grafo. Sessioni → memoria
Feedback Loop — I risultati delle query arricchiscono la wiki, nuove relazioni aggiornano il grafo, le conversazioni alimentano la memoria. Più si usa, più diventa preciso.
Non un miglioramento incrementale. Un approccio architetturalmente diverso.
| Dimensione | RAG Classico | PAIR |
|---|---|---|
| Trasparenza | Black box | Wiki leggibile, grafo navigabile, memoria verbatim |
| Efficienza token | Chunk grandi nel context | 71.5x meno token, 600 token wake-up |
| Struttura | Testo piatto, chunking arbitrario | Relazioni esplicite con confidence tracking |
| Determinismo | Retrieval probabilistico | AST parsing, zero hallucination strutturale |
| Memoria | Nessuna (stateless) | Persistente cross-sessione, 4 livelli |
| Privacy | Spesso richiede cloud | Tutto locale, zero dati in cloud |
| Manutenzione | Re-embedding ad ogni modifica | Aggiornamento incrementale (solo delta) |
| Costo | $500+/anno | $10-70/anno |
Il cliente carica la documentazione. PAIR::Compile genera la wiki, PAIR::Graph mappa le relazioni. In poche ore l'agente ha comprensione strutturata del dominio.
Un agente specializzato (legale, medicale, finanziario) usa PAIR come base di conoscenza. Wiki per il dominio, grafo per le relazioni, memoria per le interazioni.
L'assistente non riparte da zero. PAIR::Memory fornisce contesto accumulato, i tunnel cross-dominio collegano progetti correlati.

PAIR::Graph produce un grafo navigabile con community, dipendenze e god nodes. PAIR::Compile genera documentazione strutturata. Mappa completa in minuti.
PAIR si integra con qualsiasi agente compatibile MCP, senza riscrivere l'infrastruttura esistente.
26 tool combinati tra i tre layer. Query il grafo, cerca nella memoria, naviga la wiki — tutto via MCP.
Un singolo comando per allestire uno stack PAIR completo su qualsiasi progetto cliente.
Funziona con Claude e qualsiasi LLM con context window sufficiente. Nessun vendor lock-in.
Markdown, HTML interattivo, formati standard per grafi, vault navigabili. I dati restano tuoi.
Contatta il team R&D PiirZ per una demo o per valutare l'integrazione con i tuoi agenti.
Parliamone →